Advertisement
AI systems continue to move toward more distributed and scalable architectures, and Variational Autoencoders (VAEs) are part of that shift. Traditionally, VAEs are run locally and embedded within training pipelines or inference workflows. But with the rise of model hosting services, edge computing, and centralized deployment needs, remote VAEs—VAEs accessed through inference endpoints—have started to make sense.
The idea is simple but useful: instead of bundling a VAE model into each deployment, why not expose it as a shared, remote decoding service? This article examines how that setup works, what problems it solves, and what trade-offs it introduces.
A Variational Autoencoder is a generative model for tasks like image synthesis, denoising, or encoding latent spaces. The decoding process—translating a latent vector into a meaningful output—is often the centerpiece. Remote VAEs take that decoding capability and host it behind an API, typically through a dedicated inference endpoint. This changes how systems interact with the model.
Rather than running the VAE locally, clients send latent vectors over the network and receive decoded outputs. This allows for centralized updates, smaller deployment footprints, and shared infrastructure across services. It's not just convenient. It also improves consistency across models in production, simplifies scaling, and makes it easier to log, monitor, and audit model behavior.
This setup is especially useful in scenarios where the encoding is done on-device or at the edge, and decoding must be deferred to a more powerful or controlled environment. For instance, in federated learning setups or sensor networks, data may be encoded locally to preserve privacy and then decoded remotely for interpretation. That makes remote VAEs more than just a different packaging choice—they become a design tool in distributed AI.
The introduction of inference endpoints for VAEs changes a system's architectural and practical aspects. An inference endpoint is a managed API that hosts a machine-learning model. A few things happen when a VAE is placed behind such an endpoint.

First, latency becomes a key consideration. Decoding a latent vector is computationally light, but adding a network round-trip makes timing unpredictable. For time-sensitive applications, this requires careful monitoring and possibly caching strategies.
Second, endpoint reliability becomes crucial. If the endpoint is unavailable, decoding can’t happen. That risk pushes teams to consider high-availability deployments or fallback systems. Fortunately, most managed AI platforms now support autoscaling, redundancy, and failover mechanisms, which makes these concerns manageable but still relevant.
Third, versioning and experimentation improve. With a centralized decoder, it’s easier to roll out model updates. New VAE versions can be deployed to test endpoints, allowing controlled experiments. Teams can collect feedback across a wide range of clients without requiring those clients to update anything on their end. This allows for more frequent iteration and testing, which is helpful in fast-moving development cycles.
Lastly, logging becomes straightforward. With all decoding requests flowing through a single gateway, teams can track usage, detect anomalies, and audit outputs. That’s valuable in regulated industries or when interpretability and traceability are required.
Remote VAEs are practical in systems where the encoder and decoder are separated by design. In media compression, an edge device may encode a photo into a latent representation before sending it to a remote server for reconstruction. This reduces bandwidth and offers a layer of abstraction or privacy. The server holding the VAE decoder acts like a shared service that can evolve independently of the devices using it.
In robotics or IoT applications, lightweight sensors can send compressed data as latent vectors, deferring the heavier decoding step to a central server. This enables real-time or near-real-time operation without burdening the edge device with model complexity.
Remote VAEs are also useful in cross-device workflows. For example, a user might begin a task on one device that performs encoding and then switch to another that handles decoding. A centralized endpoint makes this seamless. It's also ideal for collaborative environments, like content generation platforms or research tools, where multiple users or agents access a shared model.
Researchers or AI developers can simplify the pipeline by using inference endpoints for VAE decoding. They can publish an encoder separately from a decoder, enabling modular experimentation. This separation is especially handy in cases like domain adaptation, where an encoder trained on one dataset can be paired with a decoder trained on another.
While remote VAEs offer flexibility, they introduce several trade-offs. The first is latency. Even if the model is fast, network delays add up. Sometimes, batching requests or running lightweight decoders locally with heavier ones hosted remotely can strike a better balance.

Security is another consideration. Latent vectors, though abstract, can still leak sensitive information depending on how the VAE was trained. Transport encryption is a must; in some cases, payload encryption adds an extra layer.
There's also the risk of becoming too dependent on the endpoint. If it's down or misbehaving, client services can fail in hard-to-debug ways. Fallback strategies like caching common decodings or bundling a minimal local model can help mitigate this.
Cost can also rise if the endpoint sees heavy traffic. Managed inference services often charge based on request volume or compute time, so budget planning becomes important.
One of the more subtle issues is data drift. If the encoder changes but the decoder stays the same, or vice versa, latent vectors may no longer decode properly. Version control becomes critical, and both sides must be tested together before deployment.
Remote VAEs with inference endpoints are a natural step in the evolution of scalable, maintainable AI systems. They offer a cleaner way to separate concerns, offload computation, and manage model lifecycles. While they bring added complexity regarding latency, reliability, and security, the benefits often outweigh the downsides—especially in environments where consistency and modularity matter. By turning decoding into a shared, centralized service, remote VAEs allow systems to be leaner at the edge and more adaptable in the cloud. Whether for media, robotics, or collaborative tools, they make decoding smarter, lighter, and easier to manage.
Advertisement
How Remote VAEs for decoding with inference endpoints are shaping scalable AI architecture. Learn how this setup improves modularity, consistency, and deployment in modern applications

How 7 popular apps are integrating GPT-4 to deliver smarter features. Learn how GPT-4 integration works and what it means for the future of app technology

Explore the top 10 LLMs built in India that are shaping the future of AI in 2025. Discover how Indian large language models are bridging the language gap with homegrown solutions
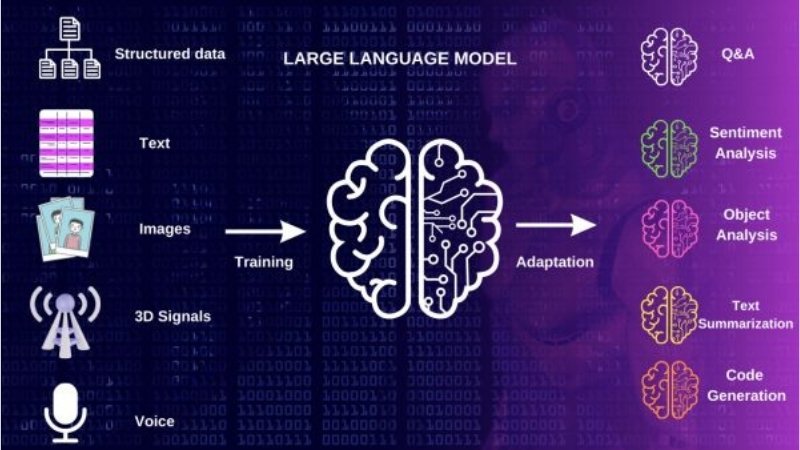
Multilingual LLM built with synthetic data to enhance AI language understanding and global communication

What happens when transformer models run faster right in your browser? Transformers.js v3 now supports WebGPU, vision models, and simpler APIs for real ML use

Curious about GPT-5? Here’s what to know about the expected launch date, key improvements, and what the next GPT model might bring

How switching from chunks to blocks is accelerating uploads and downloads on the Hub, reducing wait times and improving file transfer speeds for large-scale projects

How mastering SQL with CSVs can improve your data workflow. Use practical queries for cleaning, combining, and exploring CSV files through simple SQL logic
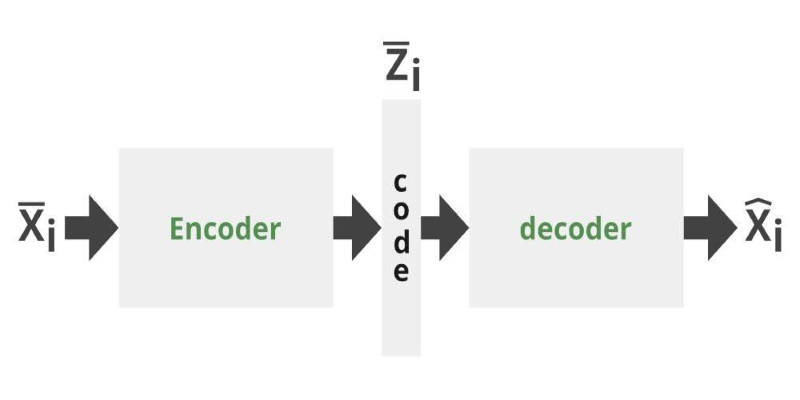
Can you get the best of both GANs and autoencoders? Adversarial Autoencoders combine structure and realism to compress, generate, and learn more effectively

How to use os.mkdir() in Python to create folders reliably. Understand its limitations, error handling, and how it differs from other directory creation methods

Windows 12 introduces a new era of computing with AI built directly into the system. From smarter interfaces to on-device intelligence, see how Windows 12 is shaping the future of tech
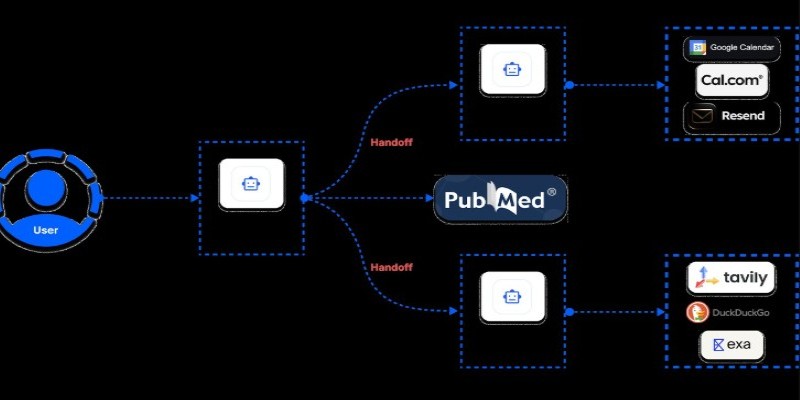
Learn how to build an MCP server using only five lines of Python code. This guide walks you through a minimal setup using Python socket programming, ideal for lightweight communication tasks