Advertisement
Computers can assist people in communicating in many languages. This is done using something called a multilingual LLM. LLM means "large language model. The large language model is what LLM refers to. It serves as a creative aid that can read, comprehend, and write in multiple languages. You can find these models assisting in chat apps, translation software, and writing tools.
Even so, the task of creating these models is challenging because we require a substantial amount of text in many different languages. Now and then, getting actual texts in a language can be difficult. For this reason, people turn to synthetic data. This refers to computer-generated text that appears to be written by a real user. The model is often trained on data that is not real text. We will explore how to use synthetic data to turn a writer's LLM into a multilingual model in this blog.

A multilingual LLM is a large computer that can read, understand, and write in a variety of languages. It utilizes information gathered from various types of texts, each written in a different language. After finishing your studies, you can start translating, answering in several languages, or drafting messages. This model is beneficial for individuals and organizations worldwide.
As an example, it could help a company contact and update customers from all over the world. It may help students learn different languages. Still, there's one big issue. There will be much text to study in some languages but less in others. This issue makes it difficult to teach the model in every language.
The reason synthetic data is important is that it provides a valuable alternative to real-world data. It allows you to work with benchmarks when you don't have real data. The following section provides further information about synthetic data and its benefits.
Synthetic data means fake data made by a computer. It is not taken from real books or websites. Instead, it is created by a machine to look like real text. This type of data is beneficial when there is a lack of authentic text in a specific language.
For example, some languages like English and Spanish have a lot of real text. Nonetheless, other languages, such as Zulu or Lao, do not. This makes it hard to train a language model for those smaller languages. With synthetic data, we can generate new text in these languages, which helps the model learn more effectively.
Using synthetic data also saves time and money. It is faster to create fake text than to collect and clean real data. It also helps keep the data safe and private because it does not come from real people. This is why many companies and researchers now utilize synthetic data to train more effective multilingual large language models (LLMs).
Creating a multilingual LLM that can write well in many languages takes a few concise steps. Let's look at each step simply.
Start by asking a simple question: What do you want the model to do? Do you want it to write blog posts, answer questions, or translate languages? After that, choose the languages you want your model to learn. For example, you may learn English, Hindi, Arabic, and French. It's important to select the right languages based on who will use your model.
Now you need data. This means lots of text in the languages you chose. You can collect real data from books, websites, or news articles. However, some languages lack extensive data. In that case, you can make synthetic data using another language model. Provide the model with some examples, and it will generate fake text that appears genuine. This helps you get enough data for every language.
Next, clean the data. This means removing extra spaces, strange symbols, or words that don't make sense. You also need to break the text into smaller parts, like sentences or phrases. This makes it easier for the computer to learn. Try to maintain the same amount of data for each language so the model doesn't become proficient in one and less so in others.
Now, it's time to choose the model. Many people use a type of model called a Transformer, which works well with language. Start the training by feeding your data into the model. This step can take several hours or even days, depending on the size of your model. The model will gradually learn to understand and write in various languages.
Once the training is done, you need to test the model. Give it tasks like writing a short story or translating a sentence. Verify that the answers are accurate and precise. Try different functions in different languages. If the model makes mistakes, you can go back, correct the data, and retrain it.
When your model is ready, you can use it in apps, websites, or tools. But your work is not finished. Watch how the model performs. If people find problems or if the model gives wrong answers, you can keep training it with better or more synthetic data. This enables the model to become smarter over time.

In conclusion, building a multilingual writer LLM using synthetic data is an innovative and helpful way to support many languages. It helps fill the gap where real data is missing, making the model work better for everyone. By following simple steps, such as collecting data, training the model, and testing it, anyone can begin building their multilingual tool.
With the help of synthetic data, we can create language models that are fair, useful, and ready to support people all around the world.
This approach makes it easier for people in different countries to use technology in their own language. It gives everyone a chance to share their ideas and stories, regardless of the language they speak. As we refine these models, we enable more people to connect, learn, and grow through language.
Advertisement

How switching from chunks to blocks is accelerating uploads and downloads on the Hub, reducing wait times and improving file transfer speeds for large-scale projects

How AI in mobiles is transforming smartphone features, from performance and personalization to privacy and future innovations, all in one detailed guide
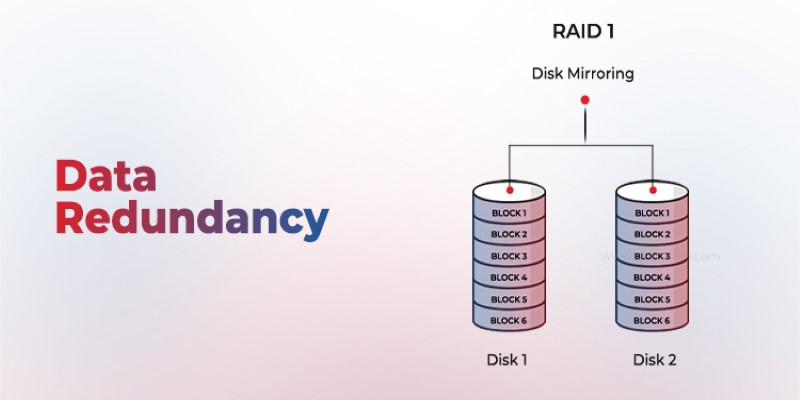
Is your system storing the same data more than once? Data redundancy can protect or complicate depending on how it's handled—learn when it helps and when it hurts

XAI’s Grok-3 AI model spotlights key issues of openness and transparency in AI, emphasizing ethical and societal impacts
Multilingual LLM built with synthetic data to enhance AI language understanding and global communication

GenAI is proving valuable across industries, but real-world use cases still expose persistent technical and ethical challenges

Curious about GPT-5? Here’s what to know about the expected launch date, key improvements, and what the next GPT model might bring

Which data science startups are changing how industries use AI? These ten U.S.-based teams are solving hard problems with smart tools—and building real momentum

Windows 12 introduces a new era of computing with AI built directly into the system. From smarter interfaces to on-device intelligence, see how Windows 12 is shaping the future of tech

How the Hugging Face embedding container simplifies text embedding tasks on Amazon SageMaker. Boost efficiency with fast, scalable, and easy-to-deploy NLP models

AI agents aren't just following commands—they're making decisions, learning from outcomes, and changing how work gets done across industries. Here's what that means for the future
How to convert Python dictionary to JSON using practical methods including json.dumps(), custom encoders, and third-party libraries. Simple and reliable techniques for everyday coding tasks