Advertisement
Autoencoders compress. GANs generate. Each does its job well, but on its own, neither offers the full picture. Autoencoders help us understand data by representing it in a lower-dimensional space. GANs skip the interpretation and go straight for realism, pushing out data that's difficult to tell apart from the real thing. The problem is that these two methods don't naturally speak to each other. That's where Adversarial Autoencoders (AAEs) come in.
AAEs create a shared ground. They learn structured representations of data and, at the same time, generate new content that mimics the patterns of the original. In short, they give us both understanding and realism in one model.
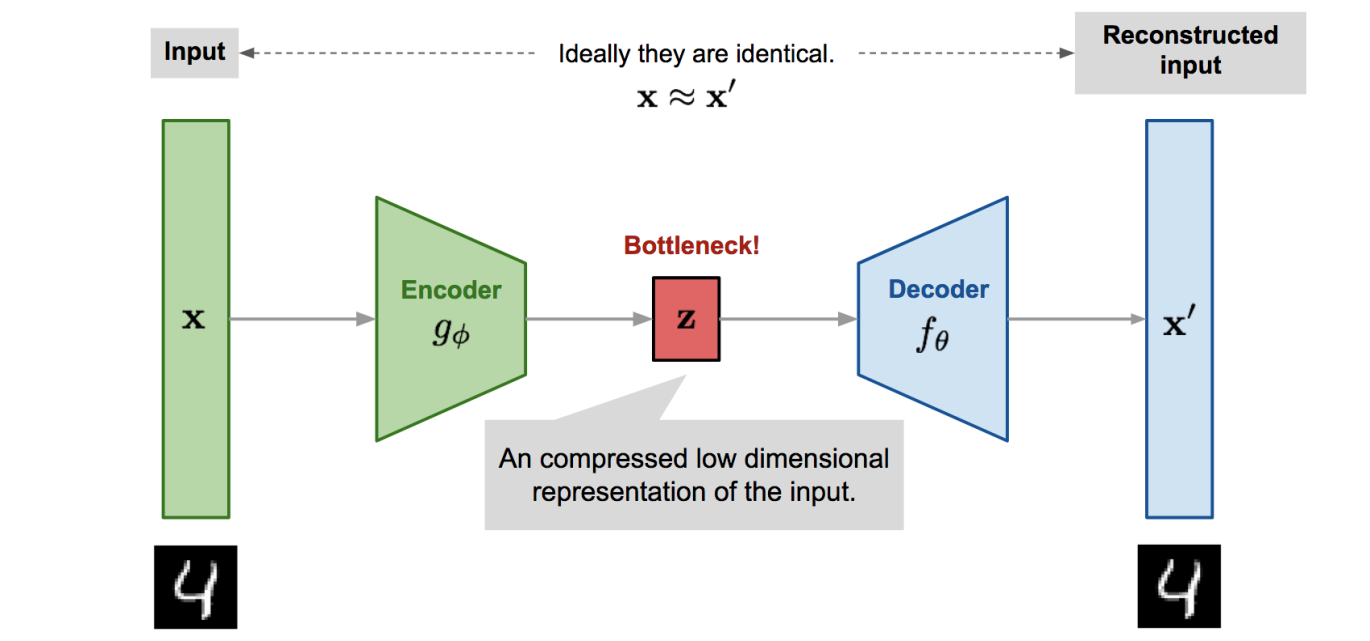
Autoencoders shrink input into a compressed version called a latent code and then reconstruct it. They’re useful in feature learning, noise removal, and dimensionality reduction. But the latent space they produce isn’t always organized in a way that’s easy to sample from. When you try, the output might not look anything like the training data—it may even fall apart completely.
GANs flip the script. They begin with a fixed distribution—commonly a normal distribution—and transform it into data that appears real. A discriminator model serves as a critic, pushing the generator to improve with each attempt. But GANs come with their own issues: they’re notoriously unstable and offer no clear way to reverse the generation process (no encoder). That means you can’t easily interpret or compress input data.
AAEs step into this imbalance. They bring the encoder and decoder from autoencoders and introduce adversarial regularization, a process inspired by GANs, to impose structure on the latent space.
At their heart, AAEs are still autoencoders. An encoder compresses the input into a latent code. A decoder tries to reconstruct the original input from that code. That much is familiar. The change comes in how they handle the latent space.
In a regular autoencoder, the latent space is shaped only by the reconstruction objective. With AAEs, another force steps in: a discriminator. This component checks whether the codes in the latent space follow a known distribution. If they don’t, it flags them. The encoder learns to produce codes that fool the discriminator into believing they are real samples from the chosen distribution.
It works like this:
Reconstruction: The encoder-decoder pair minimizes reconstruction error—just like a standard autoencoder. The better the match, the lower the loss.
Regularization: The encoder also trains to make its latent codes resemble samples from a known distribution. The discriminator plays a key role here. It learns to tell whether codes come from the encoder or the target distribution. The encoder learns to generate codes the discriminator can’t distinguish from real ones.
By bringing adversarial training into the autoencoding framework, AAEs shape the latent space intentionally rather than incidentally. That structured space is far easier to sample from and more useful for generating high-quality data.
It’s tempting to ask whether Variational Autoencoders (VAEs) already cover this ground. VAEs do regularize the latent space, yes—but through a fixed mathematical approach that relies on approximations. The outputs often blur because of that. In contrast, AAEs use a learned discriminator, which gives them more freedom to match the target distribution accurately. This flexibility often results in clearer, more detailed outputs.
Compared to GANs, the advantage is in the two-way street. GANs generate, but they don’t compress. AAEs do both. You can push input data into a compressed space, then reconstruct it—or sample from the distribution and create new data. This makes AAEs more useful for tasks that involve both interpretation and generation.
They also avoid some of the training headaches of GANs. The adversarial aspect in AAEs is limited to the latent space, not the full output. This tends to make training more stable and the outcome easier to control.
To train an AAE, the process needs to alternate between reconstruction and regularization. Each step plays a distinct role.
You’ll need:
The encoder and decoder are optimized together during reconstruction. The discriminator and encoder work in opposition during the regularization step.
Input data is passed through the encoder and then the decoder. The model calculates how close the output is to the original input using a reconstruction loss (like MSE or binary cross-entropy). The weights of both the encoder and decoder are updated based on this loss.
Now, focus on the latent space. Take one set of samples from the encoder’s latent outputs. Take another from the actual target distribution (e.g., Gaussian). Feed both to the discriminator. It learns to classify which is which. The encoder isn’t touched in this step.
Now freeze the discriminator. Train the encoder to make its latent codes indistinguishable from the real samples. The loss here comes from the discriminator's prediction and pushes the encoder to match the distribution more closely.
This cycle repeats reconstruction, discrimination, and adversarial encoding. Each part reinforces the rest.
Adversarial Autoencoders aren’t just a bridge—they’re a distinct type of model that solves practical problems in representation and generation. They take the strong parts of autoencoders and GANs but combine them in a way that reduces the limits of both.
By focusing adversarial learning on the latent space, AAEs keep training stable and results consistent. They offer clean encoding, clear decoding, and a way to shape the space between.
Whether you're working on generative design, predictive modeling, or data exploration, AAEs provide a reliable and scalable approach to making sense of complex data while still creating something new from it. They strike a balance—not by compromise, but by structure.
Advertisement

Windows 12 introduces a new era of computing with AI built directly into the system. From smarter interfaces to on-device intelligence, see how Windows 12 is shaping the future of tech

Curious about the evolution of Python? Learn what is the difference between Python 2 and Python 3, including syntax, performance, and long-term support

Which data science startups are changing how industries use AI? These ten U.S.-based teams are solving hard problems with smart tools—and building real momentum

Explore the top 10 LLMs built in India that are shaping the future of AI in 2025. Discover how Indian large language models are bridging the language gap with homegrown solutions

Want to run AI models on your laptop without a GPU? GGML is a lightweight C library for efficient CPU inference with quantized models, enabling LLaMA, Mistral, and more to run on low-end devices
Multilingual LLM built with synthetic data to enhance AI language understanding and global communication
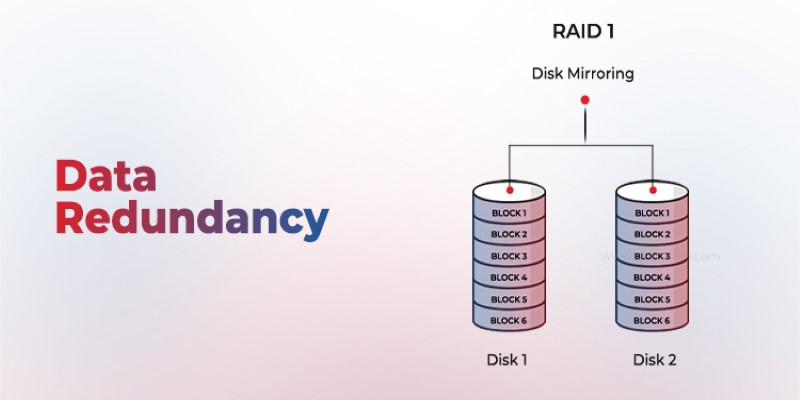
Is your system storing the same data more than once? Data redundancy can protect or complicate depending on how it's handled—learn when it helps and when it hurts

A step-by-step guide on how to use Midjourney AI for generating high-quality images through prompts on Discord. Covers setup, subscription, commands, and tips for better results

Discover 10 job types AI might replace by 2025. Explore risks, trends, and how to adapt in this complete workforce guide.

GenAI is proving valuable across industries, but real-world use cases still expose persistent technical and ethical challenges

How the Hugging Face embedding container simplifies text embedding tasks on Amazon SageMaker. Boost efficiency with fast, scalable, and easy-to-deploy NLP models

See how Intelligent Process Automation helps businesses automate tasks, reduce errors, and enhance customer service.